| spanish.china.org.cn | 05. 06. 2024 | Editor:Teresa Zheng |  |
 |
 |
 |
 |
[A A A] |
Disculpas de un equipo de Stanford por plagio de modelo chino de IA
Un equipo de inteligencia artificial (IA) de la Universidad de Stanford se disculpó por plagiar un gran modelo de lenguaje de una empresa china, en un caso tendencia en las redes sociales chinas que causó inquietud entre los internautas el martes.
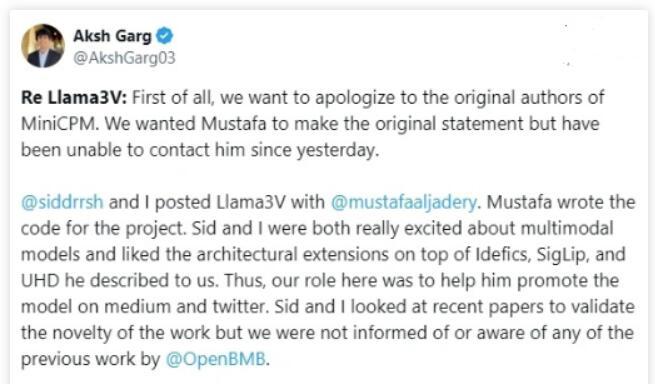
“Pedimos disculpas a los autores del MiniCPM por cualquier inconveniente que hayamos suscitado al no verificar y revisar la originalidad del proyecto", escribieron los responsables del modelo multimodal Llama3-V en una publicación en la plataforma X (antes Twitter).
El mensaje llegó después del anuncio del Llama3-V el 29 de mayo, en el que afirmaban un rendimiento comparable al GPT4-V y otros modelos con capacidad de entrenamiento por menos de 500 dólares.
Según los medios, la nota dada a conocer por uno de los miembros del equipo recibió rápidamente más de 300 000 visitas.
Sin embargo, algunos internautas de X encontraron y enumeraron pruebas de cómo su código estaba reformateado y era similar al del MiniCPM-Llama3-V 2.5, modelo de la firma tecnológica china, ModelBest, y la Universidad de Tsinghua.
Dos integrantes del equipo de Stanford, Aksh Garg y Siddharth Sharma, usaron la consulta de un usuario para disculparse el lunes diciendo que su función era promocionar el modelo en Medium y X, y que no habían podido ponerse en contacto con quien escribió el código del proyecto.
De acuerdo con la comunicación, consultaron artículos recientes para validar la novedad del trabajo, pero no fueron informados ni conocían la labor del Open Lab for Big Model Base, del Laboratorio de Procesamiento del Lenguaje Natural de la Universidad de Tsinghua y ModelBest. Indicaron asimismo el retiro de todas las referencias del Llama3-V con respecto al proyecto original.
Liu Zhiyuan, científico jefe de ModelBest, señaló en el portal chino Zhihu que el equipo del Llama3-V no cumplió los protocolos de código abierto de respeto y reconocimiento de los logros de investigadores anteriores, socavando así de manera grave la piedra angular de su intercambio.
Según una captura de pantalla filtrada en Internet, Li Dahai, director ejecutivo de ModelBest, también publicó una nota en su momento en WeChat, en el que sostenía que se había verificado que los dos modelos tenían una gran similitud en las respuestas e incluso en los errores, y que algunos datos relevantes aún no se habían hecho públicos.
Añadió que el equipo espera que su trabajo reciba más atención y reconocimiento, pero no de esta manera, y abogó por un entorno comunitario abierto, cooperativo y de confianza.
El director del Laboratorio de Inteligencia Artificial de Stanford, Christopher Manning, también respondió a la explicación de Garg el domingo, comentando “¡Cómo no asumir los errores!” en X.
Cuando el incidente ganó tracción en Sina Weibo, los internautas chinos opinaron que los estudios académicos deben partir de hechos, pero que el incidente demuestra además que el desarrollo tecnológico chino avanza.